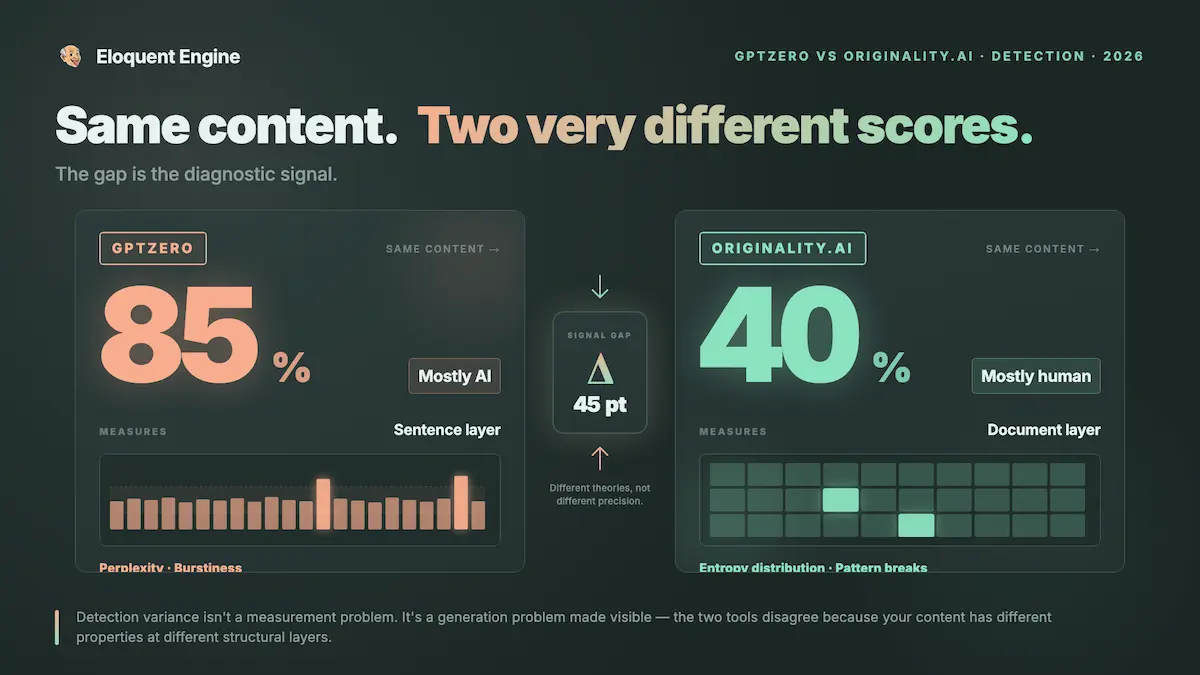
Your Content Scored 85% on GPTZero and 40% on Originality.ai. That Gap Is Telling You Something.
“Which detector is more accurate?” presupposes GPTZero and Originality.ai are measuring the same property with different levels of precision. They’re not. The question encodes a false assumption, and as long as we operate inside it, the comparison produces nothing useful.
Same content. Two tools. One flags it at 85%, one at 40%. This variance is signal—actual diagnostic signal telling you exactly what each system found when it looked at your content through its particular measurement lens. The variance isn’t the problem. The variance is the information.
Here’s the objection I hear most: understanding detector mechanics won’t change the fact that you’ll still edit AI output. And that’s worth taking seriously, because it’s partially true. You will still edit. But knowing why scores diverge changes what you edit, how early you catch it, and whether you’re fixing the right layer of the problem. The editing is a symptom. You can’t address a symptom efficiently without understanding what’s causing it.
GPTZero and Originality.ai encode different theories about what AI-generated text looks like. Not different accuracy levels of the same theory. Different theories entirely. The gap between their scores on the same piece of content is those two theories disagreeing about what they found. Once you understand what each theory predicts, the gap stops feeling like a trap and starts functioning like a diagnostic tool you actually control.
A prompt library is not a content strategy. And running content through two detectors without understanding what either one measures is not a QA process. Both are blind approaches to problems that have specific, knowable causes.
What GPTZero actually measures, and why its scores can feel extreme
GPTZero scores the same text at 84% AI while ZeroGPT scores it at 19%. That’s 65 percentage points on identical input, and it’s been reproducible across enough Reddit threads on r/ChatGPT and r/studytips that calling it an edge case stopped being defensible a long time ago. The tools evaluated on feature lists and pricing while the actual output is garbage – that’s the detection category in miniature. Marketing precision, operational chaos.
GPTZero was built around two specific signals: perplexity and burstiness. Perplexity measures how statistically predictable a piece of text is. When a language model generates content, it selects each word based on what’s most probable given everything before it. The result, even when it sounds natural, is text that flows too smoothly. Too many expected word sequences. Too few surprising choices. Low-perplexity text is GPTZero’s primary target.
Burstiness measures how that predictability is distributed across the text. Human writing is characteristically uneven. Complexity spikes and drops. A technically dense paragraph lands next to a short, punchy observation. A long, subordinate-clause-heavy sentence gets followed by a fragment. AI writing doesn’t do this naturally. The perplexity stays in a narrow band. The rhythm is even. Burstiness detects that flatness, and GPTZero weights both signals heavily in its classification.
The practical result: GPTZero is calibrated for formal, structured writing. Academic essays. Structured reports. The content types where AI generation produces the most uniform output. A practitioner framing it as “GPTZero feels more relevant for academic style text” is describing something real. GPTZero’s sensitivity to perplexity and burstiness makes it sharp at catching that formal register, and notably less reliable on mixed text or lightly edited AI content where a skilled prompt engineer introduced sentence variation.
That’s where the extreme scores come from. GPTZero is not broken when it produces a 90% flag on content that “feels” human. It found specific statistical properties, weighted them against its model, and returned what that calculation produced. Practitioners are using a tool calibrated for academic detection on SEO blog content and treating the output as universal truth.
Whether GPTZero’s extreme scoring reflects sensitivity or poor calibration depends entirely on what you’re running through it. For formal content, the sensitivity is probably appropriate. For mixed or conversational content, those scores reflect a model encountering something it wasn’t fully calibrated to evaluate. That’s a use-case mismatch, and knowing the difference protects you in the client conversation.
What Originality.ai actually measures, and why I used to think it was just “more accurate”
I’ll be honest: the first time I ran the same piece through both tools and got wildly different scores, my instinct was that Originality.ai was simply the better-calibrated tool. The scores felt closer to what I expected. Less extreme. More like what practitioners mean when they say it “landed closer to what felt accurate.” I assumed that feeling was evidence of precision.
In hindsight, I was probably confusing consistency with accuracy—different properties entirely.
Originality.ai’s detection engine focuses on entropy distribution and writing pattern breaks rather than perplexity and burstiness. Entropy, in this context, measures informational unpredictability across the text. High entropy means diverse vocabulary, varied structural choices, transitions that don’t follow obvious patterns. Low entropy means the text is making safe, statistically expected choices throughout. Originality.ai’s model was trained to detect the specific entropy signatures that characterize output from large language models – particularly GPT-4 and similar architectures.
The writing pattern break signal is where it gets more interesting (and, to be honest, more complicated). Human writing has inconsistencies. Shifts in formality. Changes in how arguments are structured from section to section. A sudden personal aside in the middle of an otherwise neutral explanation. These inconsistencies are signatures of a mind working through something in real time. AI writing, especially when it’s prompted section by section or generated in a single pass with a generic brief, tends to maintain a consistent register throughout. Originality.ai’s model is partially calibrated to detect the absence of those breaks.
Here’s what I kept missing: most detectors show high false positives on human writing and easy misses on lightly edited AI text. That’s the actual calibration failure in the category. If the content you’re producing is lightly edited AI output – which, let’s say it plainly, is what most agency production looks like right now – Originality.ai’s entropy model is genuinely more sensitive to what you’re producing than GPTZero’s perplexity model is. That’s why its reputation for consistency is real. But consistent at what? Catching the entropy pattern of GPT-4 output. That’s a specific thing. It’s useful if that’s what you’re generating. It’s less useful if your actual risk is inconsistent human-AI mixed content.
If you built a whole prompt library and still got flagged, I think the prompt library was targeting the wrong signal. You were probably optimizing for sentence variation – which helps with burstiness and GPTZero – while the entropy distribution across the full document stayed flat. The reason AI writing sounds detectable goes deeper than sentence-level patterns, and fixing it at the sentence level leaves the document-level signals intact.
Where GPTZero and Originality.ai actually diverge, and why I’m still not sure how much that matters
To be honest, mapping the signal differences is easier than knowing what to do with the map. So let me try to be specific about what each tool catches reliably and where each one breaks down, and then sit with the parts I’m less certain about.
The clearest divergence: GPTZero is more sensitive to sentence-level statistical predictability. Originality.ai is more sensitive to document-level pattern consistency. Content can pass one test and fail the other simultaneously, because the tests are not redundant. A piece with varied sentence structure and vocabulary – the kind of output a skilled prompt engineer produces by encoding sentence length variation into the brief – will reduce GPTZero’s burstiness flag while leaving Originality.ai’s entropy signal largely unchanged.
| Signal | GPTZero | Originality.ai |
|---|---|---|
| Primary detection layer | Sentence-level perplexity and burstiness | Document-level entropy and pattern breaks |
| Strongest content context | Formal, academic, structured writing | Long-form SEO and editorial content at scale |
| False positive risk | Higher on formal human writing | Lower overall, but misses lightly edited AI |
| Mixed content behavior | Extreme scores common (“mostly AI” or “mostly human”) | More graduated scoring, less likely to spike |
| Calibration basis | Academic and essay-style detection | Commercial content, GPT-4 output signatures |
I probably overcorrected for a while by treating Originality.ai as the default trustworthy tool and GPTZero as noise. In hindsight, that was missing the point. GPTZero’s extreme scores on academic-style content are not miscalibration; they’re the signal the tool was built to produce. The match between tool and content type is wrong.
Detection variance is not a measurement problem. It’s a generation problem made visible.
That’s the thing I kept editing around instead of addressing. The two scores diverge because the content has different properties at the sentence level versus the document level. Those properties came from the generation process. The detectors revealed the gap that was already present in the generation process.
GPTZero vs Originality.ai: which signal matters for your specific use case
AI detection fires on pattern, and generic prompts produce predictable patterns. That’s the mechanism—not opinion but observable process. A blank prompt generates uniform output because the model has nothing brand-specific to draw on; it falls back on the statistical center of its training data. That center is exactly what both detectors were calibrated to find.
So the question of which tool matters more for your use case is really a question about which detection layer your content is most exposed to, and that depends on what you’re producing and for whom.
SEO blog content published at scale
Originality.ai is the harder test here. Long-form SEO content is precisely the content type it was built to evaluate, and its document-level entropy analysis catches the structural uniformity that emerges when you’re publishing at volume without a brand context document. If your clients are in sectors where competitors use Originality.ai for content audits – and increasingly, SEO-focused clients are – this is the score that will follow you into a client conversation. Benchmarking detection scores on a sample before scaling a new prompt template is not optional at this volume; it’s how you find out before the client does.
Formal, structured content with a professional register
GPTZero is the harder test here. White papers, case studies, formal reports, grant-style writing. The content types where AI generation naturally produces the flat burstiness profile GPTZero is calibrated to catch. An 80% “human-written” result on GPTZero for this content type doesn’t predict what Turnitin or a human editor will find – and it certainly doesn’t predict what Originality.ai will say. The tools are not interchangeable. Running formal content only through Originality.ai and feeling confident is a narrow miss waiting to happen.
Brand copy and mixed-register content
This is where both tools have genuine limitations. Mixed text – content that blends AI generation with meaningful human editing or integrates founder voice – is the category where false positives are highest and confidence in any score is lowest. A brand context document encoded into the brief before generation changes your output and your odds simultaneously; it introduces the vocabulary, register shifts, and pattern breaks that both tools use as proxies for human authorship.
The brands that own search in three years are building content architectures, not publishing blog posts at scale. Detection resistance is a byproduct of that architecture, not a goal you optimize for separately. If your content system requires a humanizer pass before you feel safe publishing…
The mechanics behind humanizer tools explain exactly why that pass is a second product selling you a fix for the first product’s failure. The input was wrong. The humanizer doesn’t know what the input was supposed to be. It can only mask; it cannot rebuild.
How to explain the score gap to a client without sounding defensive
I’ve watched the detection score come back at 90% and had no explanation for the client. That silence is worse than any score. And in hindsight, the reason I had no explanation was that I’d been treating the scores as verdicts rather than measurements. Once you understand the measurement, the explanation is actually straightforward.
Here’s a process that works in the client conversation:
Step 1: Name the tools as distinct measurement systems
“GPTZero and Originality.ai measure different things. GPTZero is looking at whether individual sentences are statistically predictable. Originality.ai is looking at whether the document’s overall structure follows AI-generated patterns. A piece of content can score differently on each because it has different properties at those two levels.”
This repositions you as the person who understands the tools, not the person defending the output.
Step 2: Identify which layer the score is reflecting
If the GPTZero score is high and Originality.ai is moderate, the sentence-level burstiness is the issue. The content is too uniform at the sentence level – probably because the prompt didn’t encode voice variation or the editing pass was light. If Originality.ai is high and GPTZero is moderate, the document structure is too consistent – same information architecture across every section, no register shifts, no writing pattern breaks.
Each of those has a specific upstream fix. Neither fix is “run it through a humanizer.”
Step 3: Separate detection scores from ranking outcomes
Clients conflate detection with penalty. They need a clean separation. Google’s actual position on AI content is more nuanced than the fear suggests – detection by a third-party tool has no direct pipeline to a ranking signal. Originality.ai flagging content at 78% does not trigger a manual action. What triggers ranking consequences is content that fails E-E-A-T criteria: thin coverage, no entity depth, no demonstrable authority. Those are addressable in the brief. They’re not properties the detector created.
The gap between scores is telling you where your system broke
Every agency that has published 200 articles a month and called it a content strategy eventually hits this moment. The client runs the content through Originality.ai. The score comes back high. There’s no explanation ready, no framework in place, no process that predicted this would happen. Just the score and the silence.
The detectors did exactly what they were built to do—they found patterns in the content that are statistically consistent with AI generation. They found patterns in the content that are statistically consistent with AI generation. Those patterns were in the content before the detector ran. They came from the generation process. A blank prompt fed to a model with no brand context document produces hollow, detectable output because the model has nothing differentiating to encode. The detector just reads what’s already there.
Here’s the objection I want to address directly: “I’ve been doing this for two years and my scores are fine, so this doesn’t apply to me.” Maybe. Or maybe your clients aren’t running detection yet. Or they’re using the free GPTZero tier, which catches the most obvious patterns and misses the rest. The score you’re comfortable with today is calibrated against tools your clients used last quarter. Originality.ai’s model is updated. GPTZero’s sensitivity to formal content is real. “Junior staff running free tools and nobody checking the output” is a description of where most agencies are right now, and it’s a description of a gap that closes without warning when a client upgrades their audit process.
The agencies that stop being surprised by detection scores are not the ones who found a better humanizer. They’re the ones who built brand-encoded briefs into the generation step, documented voice with real examples from founder communications and customer language, and stopped treating post-processing as a substitute for upstream context. The gap between GPTZero and Originality.ai on your content is not random. It’s a specific readable signal about which layer of your generation process is broken.
Fix the layer. The scores follow.
Where this comparison actually ends up
I’m genuinely uncertain whether understanding detector mechanics is enough to change behavior. Knowing why variance exists is valuable. Whether it shifts a workflow that’s been built around editing output rather than encoding input – that’s a harder question, and I don’t want to oversell the leverage here.
But here’s what the argument arrived at, somewhere past where it started: the GPTZero vs Originality.ai comparison is not ultimately a comparison between two detection tools. It’s a diagnostic instrument for your content architecture. Two tools measuring different signals and finding a wide gap means your content has inconsistent properties at multiple structural levels. That’s an upstream finding about generation, not a downstream judgment about which score to trust.
The path forward is not choosing the detector your clients fear less. It’s building a content system that encodes brand context, calibrates voice at the brief level, and produces topically coherent, structurally sound output before any detector sees it. Understanding what triggers AI detection is the foundation for that system. The score comparison just shows you which foundation is missing.
Detection scores are a symptom. The disease is generation without context. Content architecture built around brand encoding from the first word makes this comparison, over time, irrelevant.

