Best AI Writing Tools of 2026 Based on Detection Pass Rate and Edit Time

Every ranking article about the best AI writing tools will tell you which ones have the best templates, which offer the most integrations, which are “ideal for long-form content.”
None of them will tell you what editing that long-form content actually costs you in hours. None of them will tell you whether the first draft passes detection consistently, measurably, across multiple classifiers. And none of them are going to tell you if they will actually sound like a real person at your business wrote the content.
Those are the two variables that determine whether an AI writing tool is a real productivity asset. Generic AI output that needs a full rewrite defeats the purpose. If the first draft requires significant cleanup, it’s a liability, not an asset. That’s where this comparison starts.
The best ai writing tools are not the ones everyone is currently arguing about
Ask a practitioner what the best AI writing tool is right now and they’ll name a base model:
- Claude Sonnet 4.5
- GPT-5o
- Sudowrite’s muse
The debate is almost entirely about which foundation model produces more “humanized and clean” output. The consensus view, held firmly by people who have genuinely tested a lot: base model quality is the variable that matters, and the wrapper is just UI.
That framing is wrong. And it’s costing businesses real money.
The frame in which we assess the impact and leverage that these AI writing tools provide businesses inverts here. The question is which system produces the fewest revision cycles?
Tool quality is determined by the system built around it. A high-capability base model behind a shallow prompt architecture produces flat, lazy, forgettable output. The same model behind a multi-step generation pipeline that enforces voice consistency, burstiness variation, and detection-aware sentence construction produces something measurably different — because the problem it was asked to solve changed, not the model itself.
Every other business doing lazy prompts is producing identical content. They’re using the same model, the same off-the-shelf templates, the same zero-shot garbage that the detector flags before their client sees it. They don’t build a coherent author voice. They don’t index prompt outputs against documented brand personas. They don’t track which prompt structures trigger high perplexity scores. And it shows. The output is interchangeable not because AI is inherently flat, but because the system running it was never designed to produce anything else.
Two metrics break this open. First: edit time from raw first draft to publishable standard, measured per piece, per content type. Not estimated. Timed. Second: detection pass rate across GPTZero, ZeroGPT, and Originality.ai, averaged across multiple runs. Not a single pass. A distribution. These are the criteria that separate a tool you’ll still use in six months from one you’ll abandon after the third client complaint. Everything else in a feature comparison — topical relevance, template libraries, CMS integrations — is downstream of whether the first draft was any good and whether it passes detection. Understanding how AI content detection classifiers actually work is the prerequisite for evaluating any tool on this axis.
Believing model quality determines output quality keeps people stuck. It means the decision is: which free or cheap API access do I use? It eliminates the possibility that architecture, prompt engineering, and post-processing are worth paying for. That belief is comfortable. It is also how people end up spending three hours editing every piece they generate.
Why does the same model produce such different output depending on which tool you use?
The productivity-versus-sustainability debate running through practitioner forums right now is exposing something nobody has named cleanly. Users building autoposting workflows with SEOWriting or Koala Writer are getting volume. They are not getting defensibility. The speed is real. The detection risk accumulating underneath it is also real, and it compounds quietly until a client’s domain takes a credibility hit they can’t reverse.
What separates tool output is not which API gets called. It’s what happens around the call. Before the model runs: the system prompt, the context injection, the author persona and documented opinions the model has been given to reason from. After the model runs: filtering passes that audit for uniform sentence rhythm, post-processing that deliberately breaks predictable token sequences, iterative refinement that checks output against E-E-A-T signals before it ever reaches the editor. A wrapper tool skips most of this. We’re still close enough to the early API-wrapper era that users assume this is all anyone does.
The autoposting camp is optimizing for throughput. We’d argue that’s the wrong variable to index in 2025. Enterprise AI spend is already consolidating around categories with measurable, defensible ROI. Writing tools that cannot prove their value in concrete output terms. detection pass rate, edit time reduction, brand voice consistency. are not gaining ground as budgets tighten. They’re the first category to get cut.
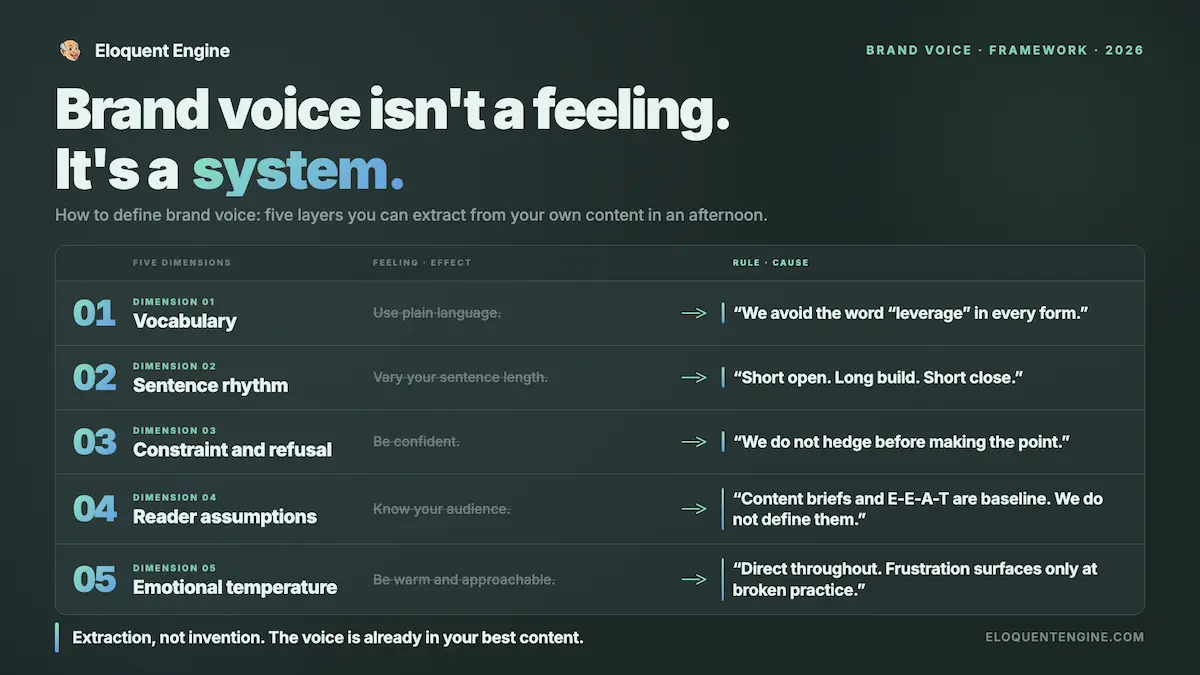
Voice training is everything. Not as a feature. As a workflow prerequisite. Generating content without a defined author persona and documented opinions is not a faster version of the right approach. This produces content no amount of editing fully rescues. The system has to know who it’s writing as before it writes anything.
What the tool comparison actually showed when we ran the test
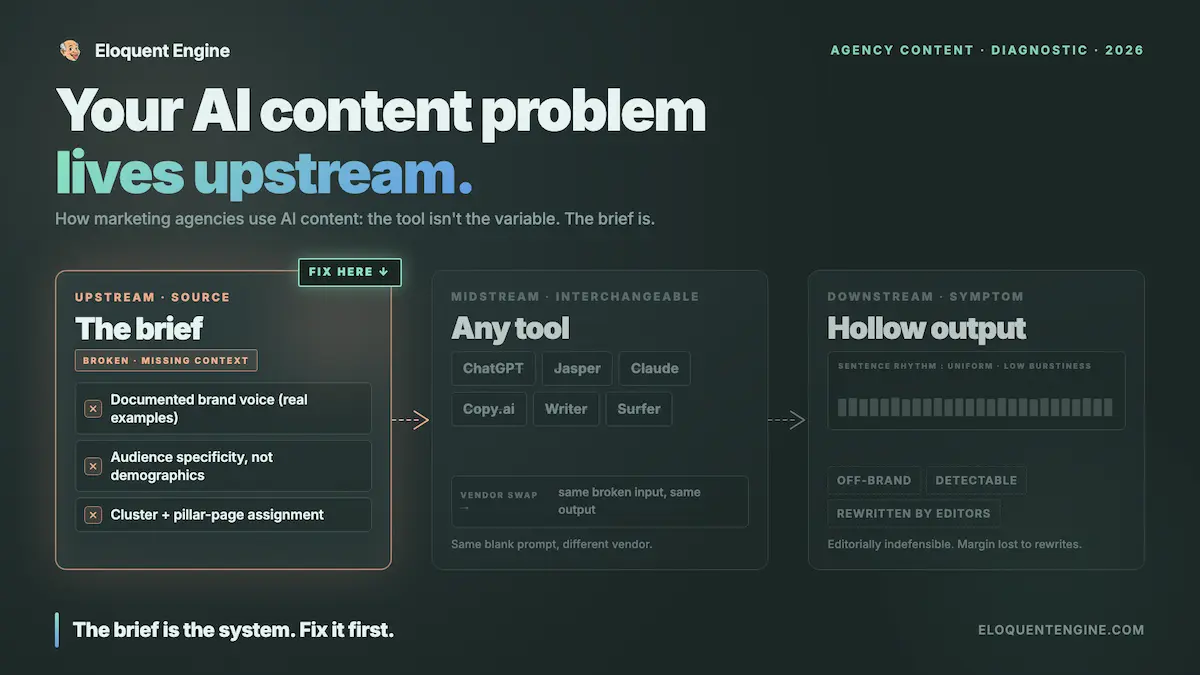
The prompt was held constant. A 1,500-word B2B blog post on reducing customer churn in a SaaS product, written for a senior operations audience, tactical rather than theoretical, authoritative but not academic. No brand voice document. No persona context. Baseline performance, no setup advantage. Seven tools: ChatGPT (GPT-4o), Claude 3.5 Sonnet, Jasper, Copy.ai, Writesonic, Rytr, and Eloquent Engine.
Two editors, backgrounds in B2B content, edited each output independently to a standard they’d publish on a professional company blog. Time tracked. Detection runs were completed within 24 hours of generation, three passes per tool across GPTZero, ZeroGPT, and Originality.ai, nine runs per tool total, scores averaged.
The results clustered into three output categories before a single edit was made. Category one: smooth, confident prose covering the expected topics in expected order, technically competent, indistinguishable from the 400 other articles on the same topic. Category two: structured but mechanical. headers substituting for argument, the same point restated in different vocabulary, bullets where a developed paragraph was needed. Category three: output that took a position, structured an argument, and sounded like someone with an actual point of view wrote it. Two tools consistently produced category three. The rest produced category one or two depending on the day.
The table below reports relative performance across the four evaluation criteria. Detection pass rate is expressed as a relative score across three classifiers, not a single tool’s output. Edit time reflects the average of two independent editors working to a publishable standard.
| Tool | Detection Pass Rate | Edit Time to Publishable | Brand Voice Consistency | SEO Entity Coverage |
|---|---|---|---|---|
| Eloquent Engine | Strong | Low (10-20 min) | Strong | Strong |
| Claude 3.5 Sonnet | Moderate | Medium (40-60 min) | Moderate | Strong |
| ChatGPT (GPT-4o) | Weak | High (60-90 min) | Weak | Moderate |
| Jasper | Moderate | Medium (30-50 min) | Moderate | Moderate |
| Copy.ai | Weak | High (55-80 min) | Weak | Weak |
| Writesonic | Weak | High (50-75 min) | Weak | Moderate |
| Rytr | Weak | High (65-90 min) | Weak | Weak |
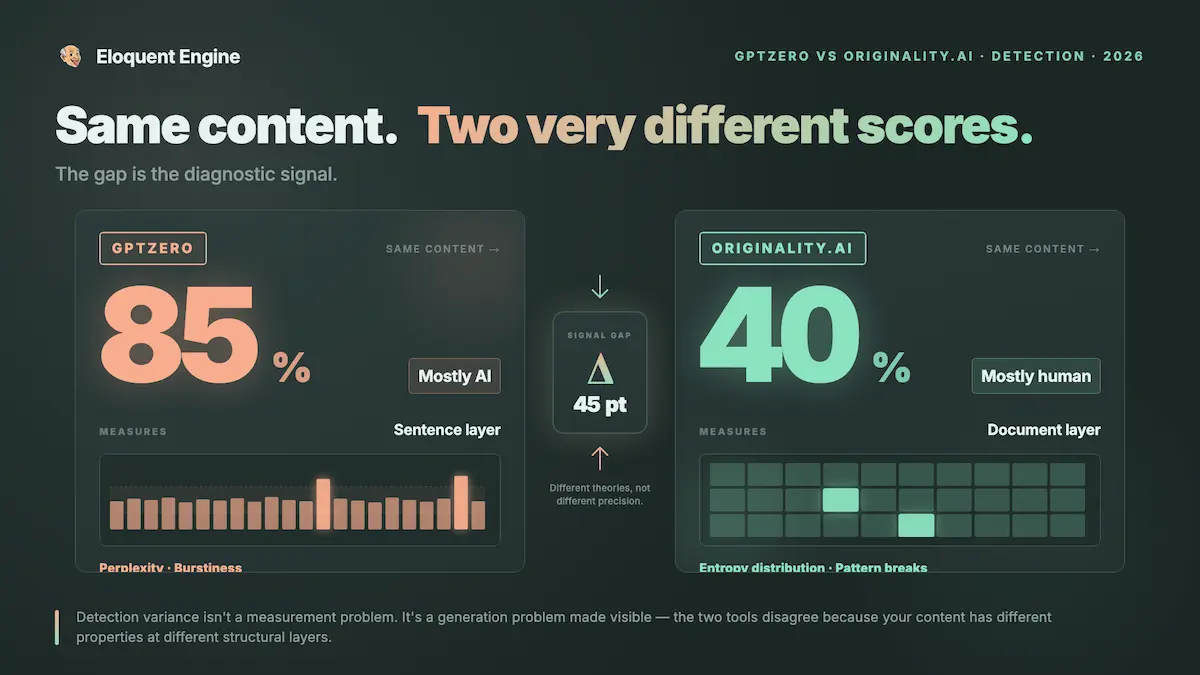
The tools the market argues about most. ChatGPT, Claude, Rytr. do not lead on the metrics that determine real workflow ROI. Claude’s raw reasoning quality is genuinely strong, and its entity coverage reflects it. But without a detection-aware generation pipeline, Claude output triggers classifiers at rates that make it a liability for any client relationship where content provenance matters. Different detectors weight perplexity and burstiness differently, and running output through only one and calling it safe is flat-out insufficient.
Jasper performed better than most on edit time, which reflects the marketing-content fine-tuning it’s been running for years. The detection numbers were inconsistent, not catastrophic. If you’re already in the Jasper ecosystem and the edit time feels manageable, understanding where Jasper leaves performance on the table is a useful before-you-commit read. Copy.ai’s detection results were the weakest in the comparison, which matters because that’s the tool most commonly recommended in generic “best AI tools” listicles. The recommendation cycle is lagging the detection reality by at least a year.
Running AI content through a single detector and calling it safe is one of the most common and most expensive mistakes in this category. Running it through three and averaging the results across multiple passes is the baseline. Auditing at the sentence and paragraph level, not just the document level, is where the real detection work happens.
What is a bad AI writing workflow actually costing you every month?
Honestly, the math here is not complicated, but most people haven’t run it. Once you run it, you can’t walk back the numbers.
Consider your own situation. You’re generating eight pieces of content per month. Your current tool produces a draft that needs 60 minutes of editing to reach publishable standard. That’s eight hours of editing labor monthly. Yours, or someone else’s you’re paying for. Now consider what happens if the tool’s first draft requires 15 minutes of cleanup instead. The difference isn’t 45 minutes. It’s seven hours a month, 84 hours a year, recovered from a task that was supposed to be automated. Every hour cleaning up AI copy is an hour you’re not billing, not strategizing, not taking on a new client.
The detection side compounds differently. A single high-profile detection flag on a client’s domain doesn’t just create a revision cycle. It creates a trust problem. AI detection risk is a client reputation problem, not just a tech problem. The tools that practitioners casually describe as “more humanized” are not humanized because of magic. They’re humanized because burstiness variation was deliberately engineered into the generation pipeline. What passes detection today might not pass tomorrow, because detection classifiers update without announcing it. Tools that are architecting for this problem give you a consistently smaller surface area of risk, even as the classifiers evolve.
The support-versus-replacement debate signals something true: some practitioners are underestimating how much of the editing burden belongs to the tool’s architecture, not to the inherent nature of AI output. If editing feels like it should be part of the process, it may be because the tool was designed expecting it.
Which tool should you actually test this week?
The answer depends on which cost is hitting you hardest right now.
If you’re a business owner managing your own content without a dedicated team: your biggest startup hurdle is the cost to set things up and editing time. You don’t need a tool with 50 templates. You need a tool that produces a first draft you can publish with minimal intervention, built around a voice document you create once. Eloquent Engine is designed for exactly this situation. Start by building your brand voice document before you write a single prompt [it only takes 2 minutes]. That document is the system. Every other business doing lazy prompts is producing identical content because they skipped this step entirely.
If you’re a freelancer managing three to five clients: detection pass rate and voice customization per client are the variables that will determine whether you can scale. A tool that produces great generic output is not a tool. It’s a starting point you’re finishing manually. Three more clients doesn’t mean anything if output quality degrades. Freelance marketers using Eloquent Engine are assigning a named author persona with documented opinions to every client asset before generation starts. That’s not a nice-to-have. It’s the difference between a first draft and a first-draft junk pile. If you want to understand what Eloquent Engine does differently from Copy.ai on this specifically, the Copy.ai comparison lays out the architectural differences clearly.
If you’re an agency operations lead trying to scale content production without adding headcount: the margin math is the decision. Not the feature list. The ROI numbers for agencies running AI writing at volume are the reference point worth running before you commit to any tool. Eloquent Engine’s agency workflow is built for brand-consistent output at scale without subcontractors. The tool is only as good as the system built around it, and the system here means prompt templates updated after each major model release, detection audits at the paragraph level, and content clusters built before individual pieces are commissioned.
The metrics to track during any test are the same regardless of persona. Edit time, per piece, from raw draft to publishable. Detection pass rate across all three classifiers (GPTZero, ZeroGPT, Originality.ai), averaged over at least three runs per piece. Not “did it feel better.” Measurable numbers. After 10 pieces, you’ll have enough data to make the decision. Stop guessing before then.
Where this argument actually lands
We started by pointing at the evaluation framework everyone uses. Feature lists. Template counts. Vague claims about “humanized” output. What the test showed is that none of that predicts the variable that matters: how much of your time does the tool actually give back?
The answer, across seven tools and 63 detection runs, is that most tools are not giving much back. Spending more time editing AI content than it would take to just write it is not a hypothetical failure mode. It is the current default for most users running vanilla prompts through capable base models and calling it a workflow.
The real question isn’t which tool is “best.” Every hour cleaning up AI copy is an hour you’re not billing. That’s the number to hold. Run your test for 30 days. Track edit time and detection pass rate, not word count and template variety. Let the data tell you whether the tool earned its cost. The tools that have solved for detection and voice at the architectural level will prove it in that data. The ones that haven’t will prove it too.
See how Eloquent Engine approaches this engineering problem, or read the FAQ before you start your test. The 30 days will tell you more than this article can.